Inside Apple's 2023 Transformer Models
What can we learn from them? • November 16, 2023Apple's latest OSes include several transformer models that are optimized for the Apple Neural Engine. We'll take a look at how they're implemented and see if there's anything we can apply to our own models. To make that easier, I've cobbled together support for viewing them in Netron—you can try it yourself here.
While everyone is talking about AI or GPT, Apple made a point to use the words "machine learning" and "transformer" when announcing new features for this year's operating systems (iOS 17 and macOS Sonoma).
Apple has been vocal about their Machine Learning accelerator, the Neural Engine (ANE), so it's no surprise that these models are designed to leverage its capabilities.
In contrast to their normal secrecy, Apple has been fairly public about how to run the transformer model architecture on the ANE. In the past year and a half they:
- Wrote a research
article about how to optimize transformers for the ANE.
- Released code to demonstrate it in the ml-ane-transformers repo.
- Published a Stable Diffusion (text to image) implementation optimized for the ANE in the ml-stable-diffusion repo.
- They have kept this up to date too!
The models embedded in the new OS are not quite as easily inspected as a research article or GitHub project. However they are a year newer. Let's see what we can learn from them!
This is most interesting if you're familiar with transformers and how they work. However if you are just generally curious I've tried to add explainers throughout to fill in some background.
They'll look like this.
Feel free to skip them.
The Models
We'll look at two models today. One powers the keyboard autocomplete, and the other does speech to text. Both use the transformer architecture to a degree.
What is a transformer?
Transformer is an ML model architecture. This is a specific sequence of mathematical operations that the
model performs to generate a set of numeric outputs from a given set of inputs. Transformers are
particularly good at generating text since they predict new words based on all the prior words. They can
also be used for non-text problems too.
 The input and first layer of the
autocomplete model, annotated.
The input and first layer of the
autocomplete model, annotated.
We won't go too deep into the models individually, rather just highlight the interesting bits.
The Vocab Size
Model: Keyboard Autocomplete
The outputs of a transformer are a bunch of probabilities for which token out of the vocab should come next. To compute these, you need to load a large mapping from token ID to embedding vector into memory.
Vocab? Probabilities?
Transformers operate on numbers, so we need a way to translate between text and numbers. We do this by
generating a set of pieces of words (and some whole words). Each word piece (aka token) is assigned a
number, the token ID, that represents it. The group of all word pieces is the vocabulary. The outputs of a
text generation model is a probability for every token in the vocabulary that is the likelihood it is the
next token in the sequence.
One dimension of this mapping matrix is equal to the number of tokens in the vocabulary. For many models this is quite large. gpt-2 (2019) has 50,257 tokens in its vocabulary. LLaMa and Llama2 (2023) have 32,000.
Apple's autocomplete model only has 15,000. Not only is this number smaller, it is also just underneath the Neural Engine's threshold for tensor size. This means that the final computation to determine probabilities can happen on the Neural Engine instead of paying the cost to transfer to CPU.
 The inner_product here is the language
modeling (lm) head.
The inner_product here is the language
modeling (lm) head.
Lesson: If possible, keep your vocab under 16384. [1]
[1] If you don't have control of this, you can duplicate the embedding matrix and do most of the computation on ANE. Here's an example.
The KV Cache
Model: Speech to Text
When using transformers for text generation, a common way to speed them up is to use KV caching. This saves you a decent amount of computation.
What is KV Caching?
A central part of the transformer architecture is multiplying 3 matrices together. They are the Query, Key
and Value matrices. An interesting aspect about repeatedly generating text with transformers is that the
contents of these matrices is mostly the same from prediction to prediction. This means we can avoid a bunch
of computation by reusing the K and V matrices from the last token we predicted. These are the KV cache.
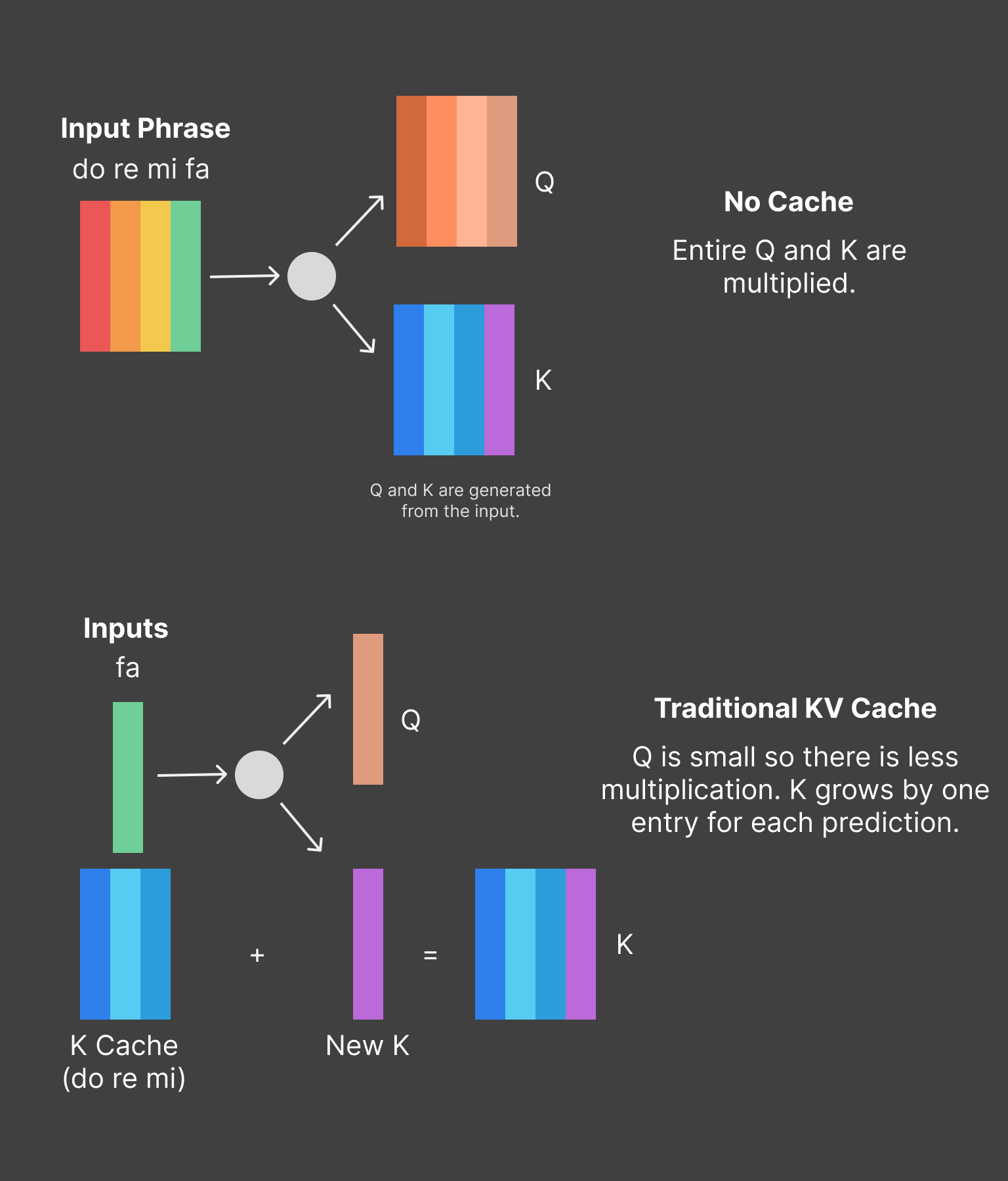 An example of how the Key (K) cache is
used. With traditional KV caching, the input is 1 token and the cache is the size of all past
tokens.
An example of how the Key (K) cache is
used. With traditional KV caching, the input is 1 token and the cache is the size of all past
tokens.
In most implementations, the size of the KV cache increments for each new token. The ANE requires that a
model's inputs and outputs are a fixed size*, which means a traditional KV cache is off the
table.
*not strictly true, but practically
You can use KV caching for any transformer model, not just text generation, and it seems that Apple has found a way to make it work for their speech-to-text model.
They have side-stepped the ANE constraints by using a fixed size input for their new tokens and sliding their KV cache by that same amount for each inference.
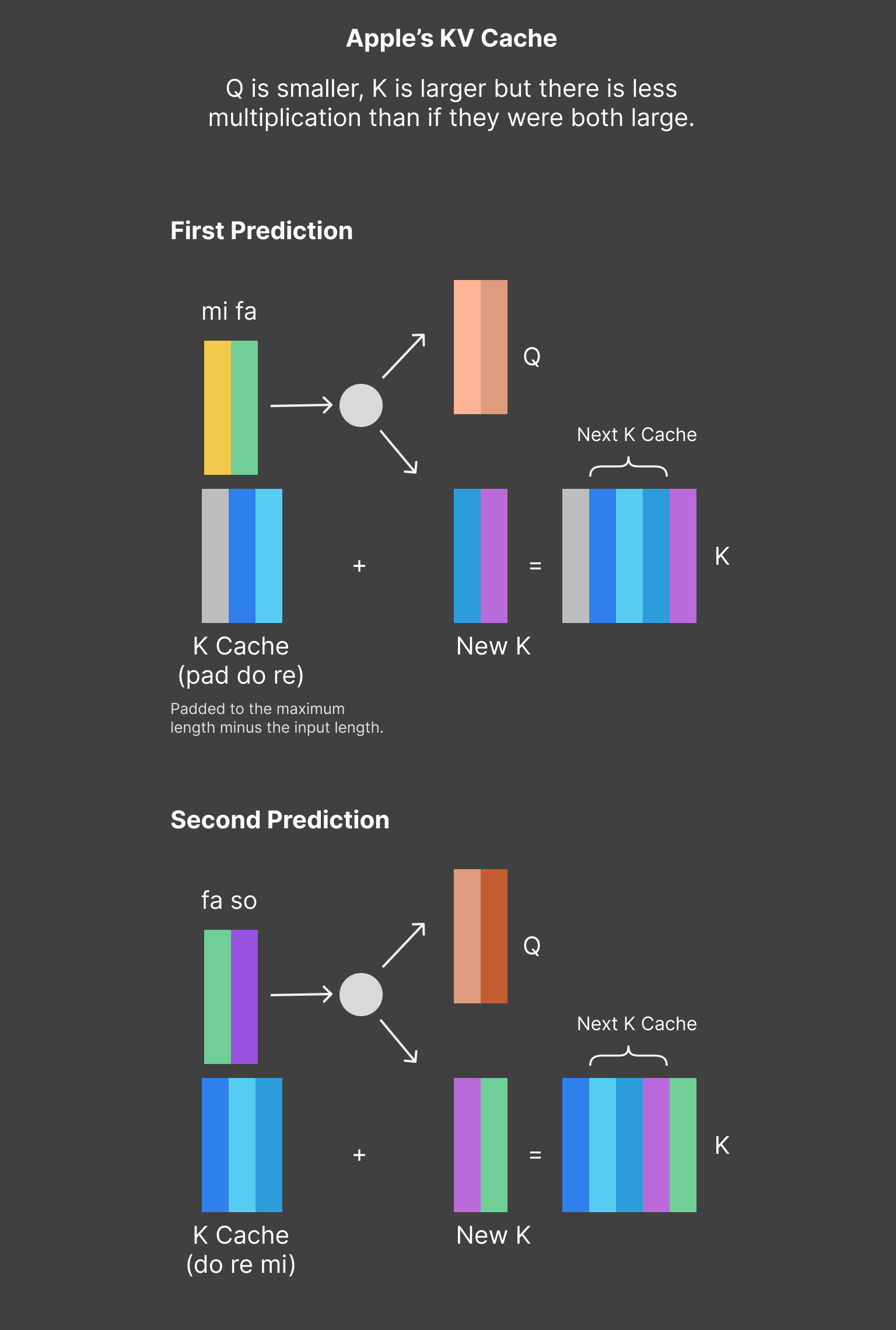 Apple's KV cache slides so that the
inputs are always the same size. In this example there are always 2 input tokens and cache that encodes
3 tokens. This gives an effective sequence length of 5.
Apple's KV cache slides so that the
inputs are always the same size. In this example there are always 2 input tokens and cache that encodes
3 tokens. This gives an effective sequence length of 5.
This gives a meaningful speed up (2-5x in my experience). However there are two caveats.
First, you have to use IOSurface-backed inputs and outputs otherwise all of the speed gained is lost again by time spent copying them in and out of CoreML. Second, if you are on Sonoma/iOS17, you can't have any CPU segments at the start of your model or it will be really slow—this seems like a regression so I have filed feedback.
Lesson: Use KV caching. If you're on Sonoma/iOS17, do your CPU work in a separate model.
Bonus: The Key Cache
The KV cache is actually a concatenation of caches for two different tensors: a Key (K) and Value (V). Often these are combined into one cache for simplicity, but Apple keeps them separate.
Why keep them separate? First, you can store the Key cache transposed instead of transposing it before using it. Transposing large tensors is extra work that you can avoid (this is in line with Apple's principle of "minimize memory copies"). Secondly, the KV cache is a large tensor and by separating it into two, you keep the intermediate tensors smaller.
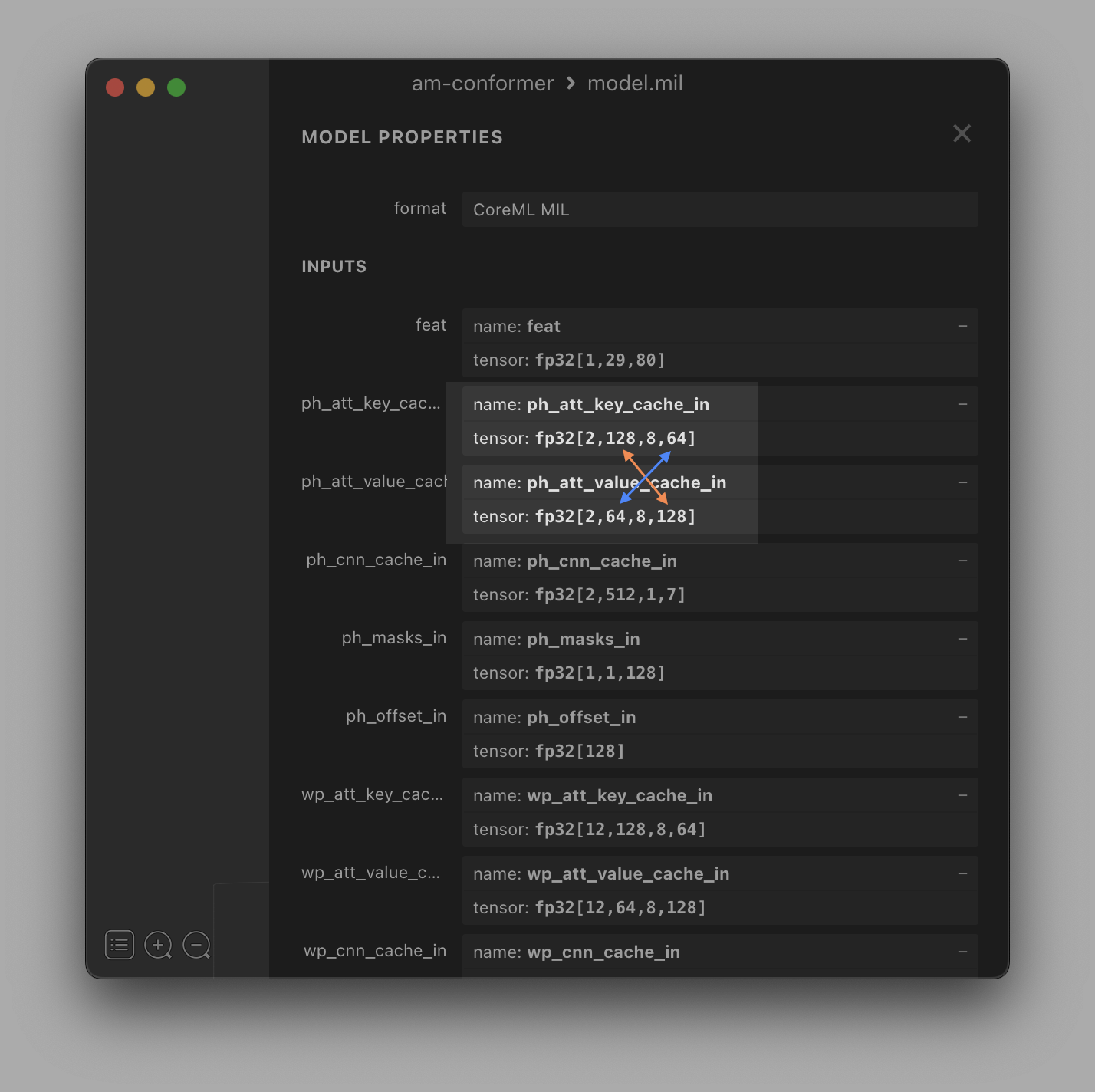 Separate caches for K and V and K is
transposed.
Separate caches for K and V and K is
transposed.
I don't see much impact from this, but it makes sense to me since you are avoiding work.
Lesson: Maybe transpose your K cache and keep it separate from the V cache.
Custom Layer Norm
Model: Both
What is a layer norm?
Layer Norm is one of the operations that a transformer model uses. It scales the values of a tensor so they
have certain statistical properties. Layer norm does this along a particular axis of the tensor.
One of the optimizations Apple recommends for the Neural Engine is to use a layer norm that normalizes along an uncommonly used axis. PyTorch's layer norm doesn't support this, so Apple provides a multi-step manual implementation.
Why does it matter what PyTorch supports?
In order to run models on Apple's devices, they need to be converted to CoreML. The easiest way to convert
them is by starting from a PyTorch (a Python ML framework) model. So if you want something, PyTorch needs to
support it. There are other ways but they are more complex.
I was curious to see what Apple used for the layer norm for two reasons. First, on Ventura/iOS 16 I found that the layer_norm (specifically the reduce_mean) caused my models to lose precision in float16. Second, CoreML has native support for layer norm along the uncommon axis and I was curious if it would be used.
Interestingly enough, it seems like Apple uses the same implementation that they open sourced in ml-ane-transformers. You can even see that most of the variable names line up!
 Almost exactly the same! I am slightly
confused by the alpha in the zero_mean though.
Almost exactly the same! I am slightly
confused by the alpha in the zero_mean though.
I was hoping for something creative here, but on the plus side it seems that layer norm is more resilient in float16 on the new OSes.
Lesson: Just use Apple's custom layer norm.
Quantization
Model: Both
Both models use quantization to reduce the size of their weight parameters. Transformer models are often bottlenecked by the amount of weight parameters they have to load and then unload. The new OSes have support for runtime de-quantization which helps reduce this bottleneck.
This can reduce the accuracy of your model, so keep an eye on that.
Lesson: Try quantizing your model. Two good sources: coremltools docs and this Huggingface/ml-stable-diffusion article.
Other Observations
There are a couple other things I noticed but I don't know how to take advantage of them. Despite that, they are still interesting in and of themselves—if you see a way to use them, please let me know!
Single Input The text autocomplete model takes 3 inputs: 128 token IDs, 128 position values and 128 segment values. It passes them to the model as one concatenated input and then immediately splits them. I'm not sure the benefit of this, but it seems slightly odd so maybe there is one?
 In the autocomplete model, the 3
embedding fields are passed as one input.
In the autocomplete model, the 3
embedding fields are passed as one input.
Shared Weights The text autocomplete model actually has two versions, one for CPU and one for ANE. They are slightly different (different inputs and outputs), but they both share the same weights. I don't believe this is currently possible using Apple's provided tooling, but it does open up some interesting possibilities. To achieve something similar today you have to ship two copies of the same weights.
$ head -n2 unilm_joint_ane.espresso.net
{
"storage": "unilm_joint.espresso.weights",
$ head -n2 unilm_joint_cpu.espresso.net
{
"storage": "unilm_joint.espresso.weights",
MultiHead Softmax Apple's implementation of the transformer in ml-ane-transformers splits a large matrix multiplication up into several smaller ones, then performs a softmax on each result (here). In contrast, the autocomplete model concatenates the results of the split matrix multiplications, performs one softmax, then re-splits that. I didn't see any performance difference from doing this, but I was only looking at speed.
Extra Outputs The CPU version of the autocomplete model outputs the next token logits, but also the pre-logit embeddings. This isn't super novel, but worth mentioning since the cost of getting already-existing data out of the model seems to be fairly low if you use IOSurface-backed buffers as mentioned above. This might be counterintuitive since some of these outputs can be rather large.
See for Yourself
Those are the eight things that stood out to me from looking at Apple's new models. Four of them are useful, four of them are just interesting.
If you'd like to look for yourself, you can find the models here on macOS Sonoma:
- Autocomplete:
/System/Library/LinguisticData/RequiredAssets_en.bundle/AssetData/en.lm/unilm.bundle - Speech to Text:
find /System/Library/AssetsV2/com_apple_MobileAsset_Trial_Siri_SiriUnderstandingAsrAssistant -name "AM-Conformer"
I have a hacky fork of Netron here that can open them (it will only open the first 3000 operations of the Speech to Text model since it is huge).
If you find anything interesting or if I misinterpreted something I would love to know. Drop me a line!